Stock Sentiment Analysis With BERT Tokeniser – Part 2
In 2018, Google introduced and very generously open-sourced BERT (Bidirectional Encoder Representation from Transformers), a powerful machine learning framework for natural language processing.
This project attempts to improve on previous attempts by tapping into the power of this potent language model using BERT tokeniser combined with a convolutional neural network for text classification.

What happened in Part 1
In Part I of this series, I used several techniques to develop a classifier that analyses and predicts stock market sentiment by reading, understanding and analysing tweets posted on Twitter by prominent investors.
The best solution in part 1 was a logistic regression classifier, trained with a Bag of Words representation. I attempted more sophisticated approaches like machine learning’s LSTM (Long Short Term Memory) and CNN (Convolutional Neural Networks) models on the dataset. The CNN provided decent accuracy during training (up to 93%) but managed to get only 72% accuracy on unseen test data .
At the time the best solution seemed to be the humble logistic regression classifier, rendering an accuracy of around 80% on unseen test data.
Getting better at it
Looking for ways to improve any model, one of the top pieces of advice will always be to ‘get more data’ to train your model on. While this is good advice and very doable in this specific use case, in real life it often just isn’t possible to get more data. By using different functionalities of BERT, I’m hoping to benefit from the pre-training as well as the bidirectionality of the language modelling system, while keeping the constraint of the limited number (+/- 6,000) of tweets.
Machine learning has the added advantage that models look at the whole sentence and so access the syntactical information contained in a sentence. The syntactical context of a sentence can assign different meanings to the exact same word based on the way it is used in said sentence.
So instead, without adding more data, I will test a couple of models to see if the syntactic context enriches the model’s understanding of the text enough so that I get better results.
But first, more about BERT
BERT (Bidirectional Encoder Representation from Transformers) is a language modelling system developed and made available to the general public by Google. The BERT architecture builds on top of the original transformer, but it uses only the encoder part, so we can say that BERT is a transformer-based model.
It is pre-trained, in an unsupervised manner, on a large corpus of unlabelled text (the entire Wikipedia spanning 2,5 million words and Book Corpus with 800 million words) to create a general language representation model. This algorithm provides us with an efficient and flexible representation for words & sentences. From this representation, it is then the task of the developer to get the most out of it for whatever problem needs solving.
BERT is also bidirectional, meaning that it learns information from both the left and the right side of a token’s context during the training phase. Put another way, BERT uses the whole sentence to predict the next word. This fully bidirectional functionality defines the training process of BERT.
Quick recap of the dataset
The Stock Market Sentiment dataset is kindly provided on the Kaggle website by Yash Chaudhary. The dataset contains approximately 6,000 tweets regarding stocks, trading and economic forecasts from twitter. Each tweet was classified as having a positive(1) or negative(0) sentiment.
Understanding the landscape
Here are a couple of definitions to help you understand the scope of the project and the environment in which it is executed. Feel free to skip to the next part if you already understand these.
Stock Market Sentiment
Market sentiment refers to the overall attitude of investors toward a particular security or financial market. It is the crowd psychology of a market, as revealed through the activity and price movement of the securities traded in that market (Investopedia). In so many words, rising prices indicate a positive, or bullish sentiment, while failing prices indicate a negative or bearish market sentiment. Understanding market sentiment can help investors make buy or sell decisions.
Although there are technical indicators, like the VIX / fear index to determine stock market sentiment, this project attempts to determine investor sentiment by analysing tweets from investors on Twitter.
NLP
Natural Language Processing, or NLP, is a branch of artificial intelligence that helps computers understand, interpret and manipulate human language. It works by converting text/words into numbers and then using these numbers in a classifier / machine learning (ML) / artificial intelligence (AI) model to make predictions.
CNN
“A convolutional neural network (CNN, or ConvNet) is a program used by computers to see things in the real world.” - Wikipedia
A convolutional neural network (CNN) is a type of artificial neural network used mainly in image recognition and processing but has also proved to be very good at processing natural language in the form or text or audio.
CNN for classification using the BERT-tokeniser
The model
As an introduction to BERT, I will simply use the BERT-tokeniser to represent the tweets and implement a convolutional neural network (CNN) to train and build a sentiment predictor.
The CNN model uses 3 different feature detectors to capture the different scales of correlation between consecutive words. The three different convolutional filter sizes are for two-, three- and four consecutive word sequences in the tweets. Each filter has the same width as the matrix because shifts are only made vertically – one word at a time. This results in an output vector (not matrix), so we will use a one-dimensional convolution layer.
Here is the summary of the model:
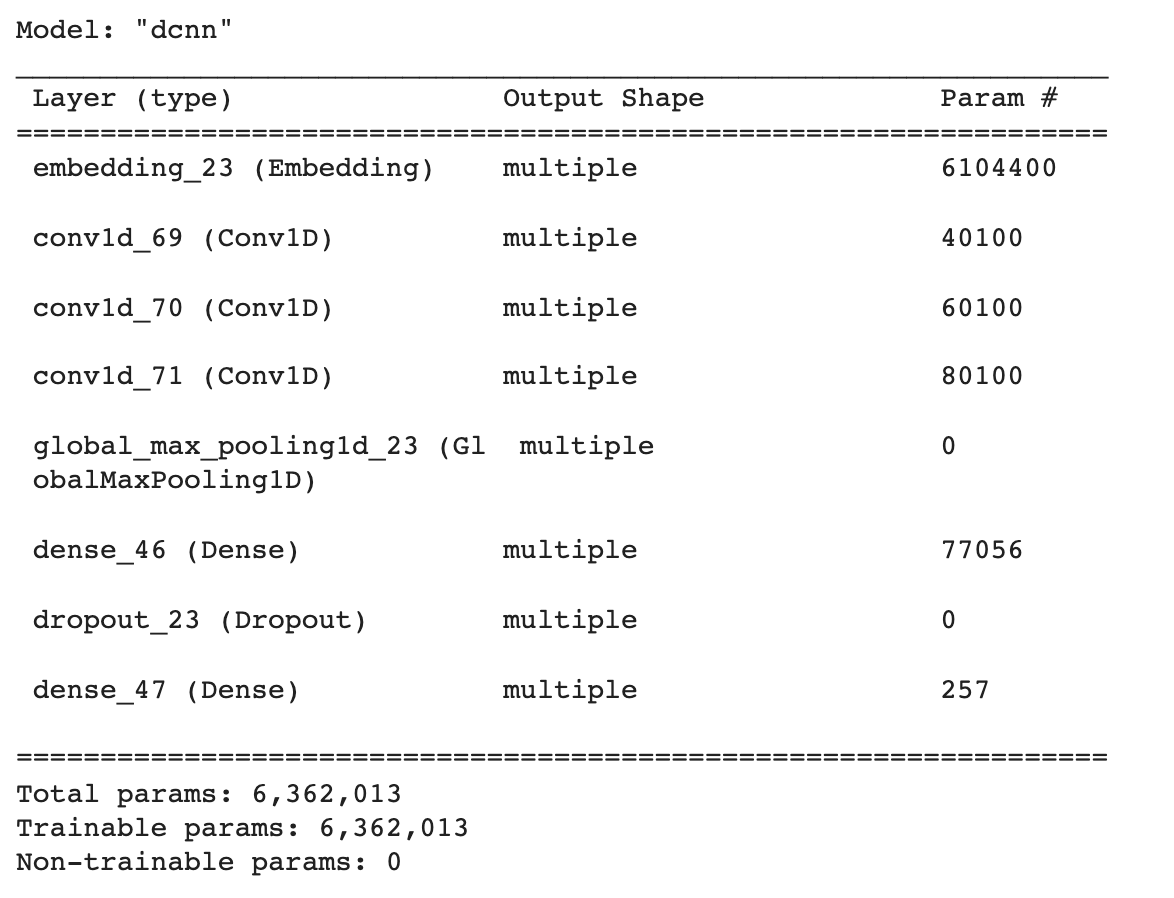
The Results

Building and training a CNN yields an accuracy of 99,9% which is higher than the CNN built and trained in part 1 of Stock Sentiment Analysis. The surprise comes, however, when we evaluate the model with an unseen test dataset. This yields an 86% accuracy on the test set, around 5% higher than the best performing logistic regression classifier in the first project.
Using the BERT-tokeniser as representation for a CNN model greatly improved the model results, with less overfitting.
Making predictions
Out of 6 randomly selected tweets, the model predicted the sentiment correctly on 4 tweets, while getting it wrong on 2 of them. While this is not nearly enough data to draw any conclusions, it does make for a good start. Being able to understand and interpret a model’s correct predictions are just as important as understanding the incorrect predictions.
Hope you enjoyed this tutorial. Stay tuned for more on BERT.